by Haytham ElFadeel - [email protected], Stan Peshterliev
2020
Research done while @ Meta Inc.
In the previous installment of this series. I talked about Multi-task pre-training to improve generalization and set new state-of-the-art numbers in machine reading comprehension, NLI and QQP while also improving out-of-domain performance. In this installment, I’m going to talk about building the best base model. As a reminder, the ROaD-Large model is based on ELECTRA architecture but with extra multi-task pre-training phase and weighted knowledge distillation.
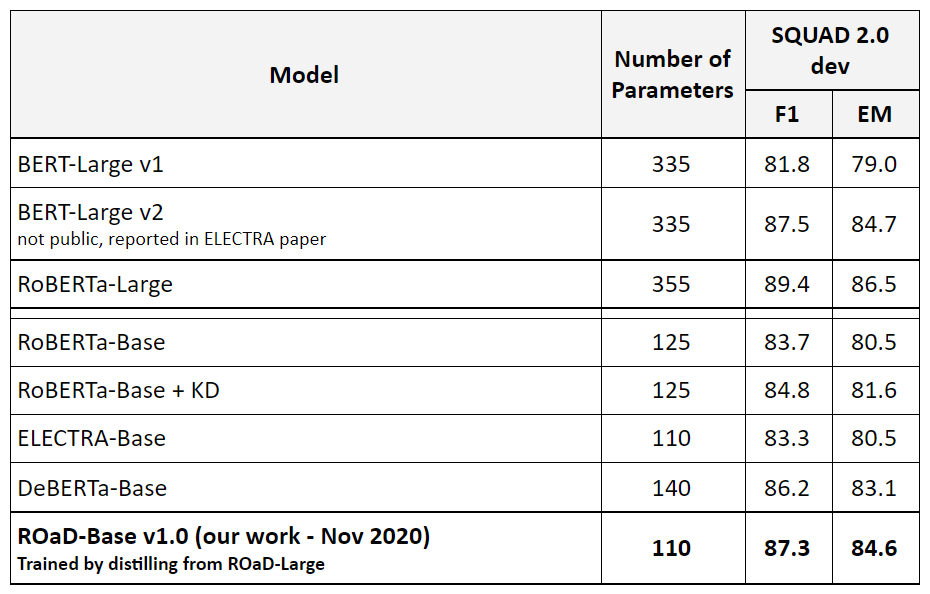
Our first version of ROaD-Base was built by simply distilling from ROaD-Large (which was trained using our multi-task pre-training and fine-tuned with weighted KD) which gave us the best base model by far (4% in absolute improvements over ELECTRA-Base, 1.5% higher than the previous state-of-the-art DeBERTa Base).
What is the best way to build base sized transformer models?! Traditionally, base models were built using the same techniques and procedures used to build the large models. But now with the proliferation of knowledge distillation we’re trying to change that. To answer this question, we did the following experiments: