By Haytham ElFadeel - [email protected]
2021
Research done while @ Meta Inc.
Transformer models (e.g. BERT, RoBERTa, ELECTRA) have revolutionized the natural language processing space. Since its introduction there have been many new state-of-the-art results in MRC, NLI, NLU and machine translation. Yet Transformer models are very computationally expensive. There are three major factors that make Transformers models (encoders) expensive:
There have been many ideas to make Transformers more performant, such as: Precision Reduction (Quantization), Distilling to a smaller architecture and Approximate Attention.
Here, we investigate another approach that is perpendicular to all other approaches (which means it can work alongside them). We call this approach Decoupled Transformer. Which decouple the inputs to improve efficiency.
The idea of Decoupled Transformer is inspired by two things:
In tasks where part of the transformer inputs doesn’t change often or could be cached, such as: Document Ranking in Information Retrieval (where the documents don’t change often), Question Answering (aka MRC) (where the passages don’t change often), Natural Language Inference Similarity matching, etc.
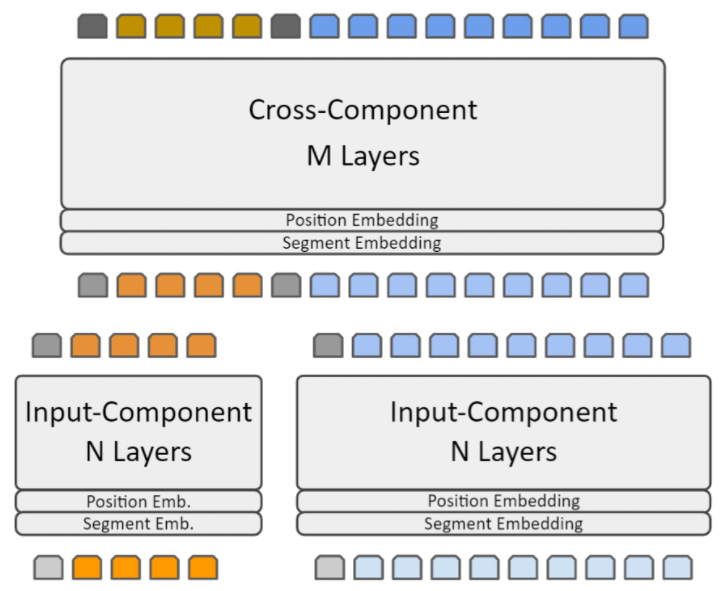
The decoupled transformer aims to reduce the inference efficiency by processing the inputs independently for part of the process and eliminating redundant computation, then process the inputs jointly for the later part of the process.
Decoupled transformer splits the transformer model into two components, an Input-Component (the lower N layers) which processes the inputs independently and produce a representation, which is cached and reused; and the Cross-Component (the higher M layers) which processes the inputs jointly (after concatenation) and produces the final output.